nginx + ingress + gunicorn 环境上传大文件报错问题的解决思路

在基于 Kubernetes 部署,使用 Gunicorn 运行的 Python Web 应用中,上传大文件时出现了一系列的错误,现在将解决问题的思路记录如下。
文件上传过程
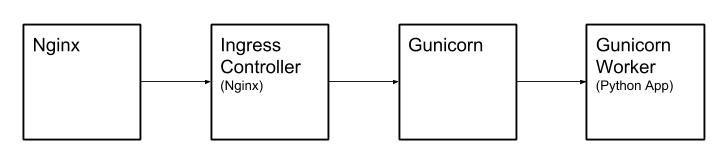
上传文件流程
- 上传的文件首先到达 Kubernetes 所在的宿主机。
- 宿主机上的 Nginx 通过 Proxy 转发给 Kubernetes 集群中的 Ingress Controller,Ingress controller 也是使用 Nginx 实现的。
- Ingress Controller 中的 Nginx 通过 Proxy 转发给 Gunicorn。
- Gunicorn 会启动若干个 Worker 处理请求,所以 Gunicorn 会再转发给 Worker。
- Worker 就是最终的 Python Web App
错误 413 的解决
首先碰到的是 413 Request Entity Too Large 错误,在上传过程中连接被中断(基本上每次都是相同的上传百分比被中断),请求返回 413,首先考虑到 Nginx 对于请求体的大小有限制,查看 Nginx 文档,发现 client_max_body_size 参数控制请求体的大小,默认的设置是 1mb。
client_max_body_size: Sets the maximum allowed size of the client request body, specified in the “Content-Length” request header field. If the size in a request exceeds the configured value, the 413 (Request Entity Too Large) error is returned to the client. Please be aware that browsers cannot correctly display this error. Setting size to 0 disables checking of client request body size.
首先在 Kubernetes 宿主机上 Nginx 的 http 域中加入如下配置。
1 | client_max_body_size 1024m; |
需要注意,除了 Kubernetes 宿主机上跑的 Nginx,还要修改 Ingress Controller 中的 Nginx。Ingress Nginx 的修改方法在 Annotation 字段中加入如下配置。
1 | "nginx.ingress.kubernetes.io/proxy-body-size": "1024m" |
错误 504 的解决
再次尝试上传,发现接口依然会返回错误,这次是 504 Gateway Timeout,从 Chrome 的开发者工具中查看请求,发现上传至少要持续5分钟,接下来从 Nginx 的超时机制入手。
在 Nginx 和 Ingress 中分别提高了读写的超时限制,将发送的超时设置为 600s,返回的超时设置为 30s。
1 | proxy_send_timeout 600s; |
再次尝试,发现依然报同样的错误 504,难道说还有别的超时字段需要设置?再次查看文档发现了端倪。
proxy_send_timeout: Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
proxy_read_timeout: Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
这里的 send 和 read,主语不是客户端,而是 Nginx 自己,超时的时候,是 Nginx 向 Upstream 发送了文件,而等到 Upstream 处理完返回时候,超过了 proxy_read_timeout 的限制,所以需要增加的是 read_timeout。
将宿主机上的 Nginx 和 Ingress 分别做如下配置。
1 | proxy_send_timeout 30s; |
1 | nginx.ingress.kubernetes.io/proxy-send-timeout: 30s |
错误 502 的解决
修改好了超时和上传文件大小的限制后,又出现了新的错误 502 Bad Gateway,这次就没有头绪了,由于是新的报错,上面的修改应该是生效了的,并且也不是上面两个限制导致的,通过查询 Nginx 和 Ingress 的日志,发现 Ingress 中有这样的报错。
1 | 2019/02/27 07:18:36 [error] 4265#4265: *19932411 upstream prematurely closed connection while reading response header from upstream, client: 172.20.0.1, server: example.com, request: "POST /upload HTTP/1.0", upstream: "http://172.0.0.1/upload", host: "example.com", referrer: "http://example.com/" |
这就比较奇怪了,刚才已经修改了超时,为什么 Ingress 还会有超时的报错呢?从日志上看,可能是 Ingress 的 Upstream 超时了,也就是 Gunicorn,Stackoverflow 上有人遇到了类似的问题,答案是给 Gunicorn 设置 -t 参数。查看 Gunicorn 的文档,timeout 参数是这么定义的。
timeout: Workers silent for more than this many seconds are killed and restarted.
Generally set to thirty seconds. Only set this noticeably higher if you’re sure of the repercussions for sync workers. For the non sync workers it just means that the worker process is still communicating and is not tied to the length of time required to handle a single request.
也就是说,当某一个 Worker 处理文件上传请求时候,如果在默认的超时时间内没有响应 Master,就会被杀掉,这也不难理解为什么 Ingress 从 Upstream 获取返回值时候连接会被关闭了。修改 Gunicorn 的配置,将超时时间设置为 600s,重新上传,问题解决。